DP-800 Exam Sample Questions | Latest DP-800 Learning Materials
Wiki Article
Our DP-800 exam questions have been widely acclaimed among our customers, and the good reputation in industry prove that choosing our study materials would be the best way for you, and help you gain the DP-800 certification successfully. With about ten years’ research and development we still keep updating our DP-800 Prep Guide, in order to grasp knowledge points in accordance with the exam, thus your study process would targeted and efficient.
Microsoft DP-800 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
>> DP-800 Exam Sample Questions <<
Using DP-800 Exam Sample Questions Makes It As Relieved As Sleeping to Pass Developing AI-Enabled Database Solutions
As you all know that practicing with the wrong preparation material will waste your valuable money and many precious study hours. So you need to choose the most proper and verified preparation material with caution. Preparation material for the DP-800 exam questions from ActualPDF helps to break down the most difficult concepts into easy-to-understand examples. Also, you will find that all the included questions are based on the last and updated DP-800 Exam Dumps version. We are sure that using ActualPDF's Microsoft Exam Questions preparation material will support you in passing the DP-800 exam with confidence.
Microsoft Developing AI-Enabled Database Solutions Sample Questions (Q28-Q33):
NEW QUESTION # 28
You have an Azure SQL database named SalesDB that contains tables named Sales.Orders and Sales.
OrderLines. Both tables contain sales data
You have a Retrieval Augmented Generation (RAG) service that queries SalesDB to retrieve order details and passes the results to a large language model (ILM) as JSON text. The following is a sample of the JSON.
You need to return one 1SON document per order that includes the order header fields and an array of related order lines. The LIM must receive a single JSON array of orders, where each order contains a lines property that is a JSON array of line Items.
Which transact-SQL commands should you use to produce the required JSON shape from the relational tables? To answer, drag the appropriate commands to the correct operations. Each command may be used once, more than once, or not at all. Vou may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
* Serialize the order-level JSON : FOR JSON PATH
* Generate a nested lines array : JSON_QUERY
* Extract a single scalar value from the JSON text : JSON_VALUE
The correct mapping is based on how SQL Server and Azure SQL JSON functions are designed to shape relational data into JSON for AI and RAG scenarios.
To serialize the order-level JSON , use FOR JSON PATH . Microsoft documents that FOR JSON PATH gives you full control over the JSON output shape and formats the result as an array of JSON objects . It is the standard way to turn relational query results into the JSON structure needed by downstream consumers such as APIs and LLM-based RAG services. It also supports nested output through subqueries and aliases.
To generate a nested lines array , use JSON_QUERY . Microsoft explains that JSON_QUERY returns a JSON object or array from JSON text, and it is used when you want to preserve a JSON fragment instead of treating it as plain text. In this scenario, the nested lines property must be emitted as a proper JSON array inside each order document, so JSON_QUERY is the correct command to embed that array in the final JSON shape.
To extract a single scalar value from the JSON text , use JSON_VALUE . Microsoft explicitly states that JSON_VALUE extracts a scalar value from a JSON string, while JSON_QUERY is for objects or arrays. So whenever the requirement is to pull out one property such as an order number, currency code, or customer ID from JSON text, JSON_VALUE is the correct function.
The unused commands are not the best fit here:
* OPENJSON is primarily for parsing JSON into rows and columns, not for shaping relational tables into nested output.
* JSON_MODIFY is for updating JSON text, not generating the required output structure.
So the drag-and-drop answers are:
* Serialize the order-level JSON # FOR JSON PATH
* Generate a nested lines array # JSON_QUERY
* Extract a single scalar value from the JSON text # JSON_VALUE
NEW QUESTION # 29
You have an Azure SQL table that contains the following data.
You need to retrieve data to be used as context for a large language model (LLM). The solution must minimize token usage.
Which formal should you use to send the data to the LLM?
- A.

- B.

- C.

- D.

Answer: C
Explanation:
The correct choice is Option A because it provides the relevant semantic context the LLM needs while avoiding an unnecessary field that would add tokens without improving answer quality.
For LLM grounding and RAG-style context, Microsoft guidance emphasizes mapping and sending the fields that contain text pertinent to the use case . In this FAQ scenario, the useful context is the ProductName , the Question , and the Answer . Those three fields help the model understand both the subject domain and the actual Q & A pair. By contrast, FaqId is just a technical identifier and generally adds no semantic value for response generation, so including it wastes tokens.
That is why Option A is better than the others:
* Option A keeps the meaningful text fields and removes the low-value identifier.
* Option B is too minimal because it includes only the answer text as Prompt, which strips away the product and question context the LLM may need for accurate grounding.
* Option C keeps FaqId but omits ProductName, which can be important disambiguating context.
* Option D includes everything, but that does not minimize token usage because it keeps the unnecessary FaqId.
NEW QUESTION # 30
You have an Azure SQL database.
You need to create a scalar user-defined function (UDF) that returns the number of whole years between an input parameter named 0orderDate and the current date/time as a single positive integer. The function must be created in Azure SQL Database. You write the following code.
What should you insert at line 05?
- A. DATEDIFF(month, @orderdate, GETDATE()) / 12
- B. DATEPART(year, GETDATE()) - DATEPART(year, @orderdate)
- C. RETURN DATEDIFF(year, GETDATE(), @OrderDate);
- D. RETURN DATEDIFF(year, @OrderDate, GETDATE());
Answer: D
Explanation:
The correct answer is D because the scalar UDF must return the number of whole years from the input
@OrderDate to the current date/time as a single positive integer . The correct DATEDIFF order is:
DATEDIFF(year, @OrderDate, GETDATE())
Microsoft documents that DATEDIFF(datepart, startdate, enddate) returns the count of specified datepart boundaries crossed between the start and end values. Since @OrderDate is the earlier date and GETDATE() is the later date, this ordering returns a positive result for past order dates.
The other choices are incorrect:
* A reverses the arguments and would return a negative value for a past order date.
* B is missing RETURN, and converting month difference to years by dividing by 12 is not the direct whole-year expression the question asks for.
* C subtracts year parts only, which can be off around anniversary boundaries because it ignores whether the full year has actually elapsed.
So the correct insertion at line 05 is:
RETURN DATEDIFF(year, @OrderDate, GETDATE());
NEW QUESTION # 31
You have an Azure SQL database that has Query Store enabled
Query Performance Insight shows that one stored procedure has the longest runtime. The procedure runs the following parameterized query.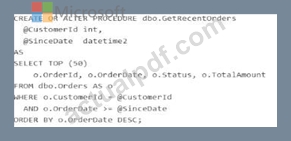
The dbo.orders table has approximately 120 million rows. Customer-id is highly selective, and orderOate is used for range filtering and sorting.
Vou have the following indexes:
* Clustered index: PK_Orders on (Orderld)
* Nonclustered index: lx_0rders_order-Date on (OrderDate) with no included columns An actual execution plan captured from Query Store for slow runs shows the following:
* An index seek on ixordersorderDate followed by a Key Lookup (Clustered) on PKOrders for customerid, status, and TotalAnount
* A sort operator before top (50), because the results are ordered by orderDate DESC For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
The first statement is Yes . The query filters on CustomerId, applies a range predicate on OrderDate, and sorts by OrderDate DESC. Microsoft's index design guidance recommends putting equality predicates first in the key, followed by columns used for ordering/range access, because the order of key columns determines seek and sort support. A nonclustered index on (CustomerId, OrderDate DESC) can support an ordered seek for this query and avoid the explicit sort. Including Status and TotalAmount helps cover the query, and OrderId is already available because the clustered key is stored with nonclustered index rows.
The second statement is No . Adding CustomerId as an included column to IX_Orders_OrderDate does not make it part of the index's navigational structure. Microsoft states that included columns are nonkey columns used to cover queries; they do not provide the seek and ordering characteristics that key columns do. So an index keyed only on OrderDate still is not the right ordered access path for WHERE CustomerId =
@CustomerId ... ORDER BY OrderDate DESC.
The third statement is Yes . The described actual plan shows an index seek on the wrong access path for the workload, followed by clustered key lookups and an explicit sort before TOP (50). That is characteristic of a suboptimal query/index plan . Query Store and Query Performance Insight are designed to surface plan- related performance regressions, while locking/blocking problems are typically identified through waits
/DMVs and blocking-session indicators, not from a plan shape like seek + lookup + sort alone.
NEW QUESTION # 32
You have an Azure SQL database that contains a table named knowledgebase, knowledgebase stores human resources (HR) policy documents and contains columns named title, content, category, and embedding.
You have an application named App1. App1 queries two relational tables named employee_pnofiles and benefits_enrollnent that contain HR data. App1 hosts a chatbot that calls a large language model (LLM) directly.
Users report that the chatbot answers general HR questions correctly but provides outdated or incorrect answers when policies change. The chatbot also fails to answer questions that reference internal policy documents by title or category.
You need to recommend a Retrieval Augmented Generation (RAG) solution to resolve the chatbot issues.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
The correct recommendation is to retrieve grounding data from knowledge_base and, at inference time, generate query embeddings and run a vector similarity search .
The chatbot currently answers some general HR questions but fails when policies change and when users ask about internal policy documents by title or category . That is exactly the kind of problem RAG is meant to solve: ground the LLM in the organization's proprietary content instead of relying on the model's training data or unrelated transactional tables. Microsoft's RAG guidance states that RAG extends LLMs by grounding responses in your own content and that, for agentic retrieval, knowledge bases unify knowledge sources for retrieval.
So the grounding data should come from knowledge_base , because that table stores the HR policy documents and already includes fields like title, content, category, and embedding. Those are the fields directly tied to the missing and outdated policy answers. By contrast:
* employee_profiles and benefits_enrollment are operational HR tables, not the authoritative store for policy-document grounding.
* PDF exports of the policies would be inferior to querying the indexed/structured knowledge base already prepared for retrieval.
* The LLM training data is specifically the wrong source when the issue is outdated internal content.
For the retrieval step, Microsoft's guidance says to use embeddings for vector queries and notes that vector similarity search matches concepts, not exact terms . This is especially important because users ask about policy documents by title or category and also phrase questions in ways that might not exactly match document wording. Generating a query embedding and then running a vector similarity search is the appropriate retrieval step in a RAG pipeline.
NEW QUESTION # 33
......
We have handled professional DP-800 practice materials for over ten years. Our experts have many years’ experience in this particular line of business, together with meticulous and professional attitude towards jobs. Their abilities are unquestionable, besides, DP-800 practice materials are priced reasonably with three kinds. We also have free demo offering the latest catalogue and brief contents for your information, if you do not have thorough understanding of our materials. Many exam candidates build long-term relation with our company on the basis of our high quality DP-800 practice materials.
Latest DP-800 Learning Materials: https://www.actualpdf.com/DP-800_exam-dumps.html
- 100% Pass Quiz 2026 Microsoft DP-800 – Marvelous Exam Sample Questions ???? Simply search for 「 DP-800 」 for free download on ▷ www.vce4dumps.com ◁ ⏫DP-800 Exam Dumps Provider
- Microsoft DP-800 - Developing AI-Enabled Database Solutions Marvelous Exam Sample Questions ???? Easily obtain free download of ➡ DP-800 ️⬅️ by searching on ( www.pdfvce.com ) ????Questions DP-800 Exam
- DP-800 Cost Effective Dumps ???? New DP-800 Exam Papers ???? Reliable DP-800 Exam Tutorial ???? Search for 《 DP-800 》 on ☀ www.examcollectionpass.com ️☀️ immediately to obtain a free download ????Test DP-800 Simulator Online
- DP-800 Exam Vce Free ↕ New DP-800 Exam Papers ???? Dumps DP-800 Cost ???? Search for ➤ DP-800 ⮘ and download it for free immediately on ⇛ www.pdfvce.com ⇚ ????Dumps DP-800 Cost
- Test DP-800 Simulator Online ↕ Actual DP-800 Test Answers ⛲ Real DP-800 Exam Answers ☃ Go to website ☀ www.prep4sures.top ️☀️ open and search for 【 DP-800 】 to download for free ????Reliable DP-800 Exam Online
- Questions DP-800 Exam Ⓜ DP-800 Exam Dumps Provider ???? Reliable DP-800 Exam Online ???? Enter ⏩ www.pdfvce.com ⏪ and search for [ DP-800 ] to download for free ????Reliable DP-800 Exam Tutorial
- 100% Pass Quiz 2026 DP-800: Developing AI-Enabled Database Solutions Authoritative Exam Sample Questions ???? Search for ➡ DP-800 ️⬅️ and download it for free on 「 www.exam4labs.com 」 website ????DP-800 Exam Dumps Provider
- New DP-800 Exam Papers ???? Best DP-800 Practice ???? Best DP-800 Practice ???? Search for 【 DP-800 】 and download it for free on 「 www.pdfvce.com 」 website ⬅Best DP-800 Practice
- Free PDF Quiz 2026 Microsoft Perfect DP-800 Exam Sample Questions ???? ▛ www.prepawayexam.com ▟ is best website to obtain ⏩ DP-800 ⏪ for free download ????DP-800 Online Training Materials
- New DP-800 Exam Papers ???? New DP-800 Exam Testking ⬅️ Best DP-800 Practice ???? The page for free download of ☀ DP-800 ️☀️ on ⮆ www.pdfvce.com ⮄ will open immediately ????DP-800 Sample Questions Answers
- DP-800 Sample Questions Answers ???? Test DP-800 Simulator Online ???? DP-800 Exam Dumps Provider ???? Copy URL ✔ www.prepawayete.com ️✔️ open and search for ➽ DP-800 ???? to download for free ????DP-800 Cost Effective Dumps
- deweyzfhs999385.angelinsblog.com, thegreatbookmark.com, exactlybookmarks.com, bookmarkfly.com, mayadnok195622.webbuzzfeed.com, bookmarkquotes.com, blakeunuk668355.blogacep.com, yxzbookmarks.com, www.stes.tyc.edu.tw, www.stes.tyc.edu.tw, Disposable vapes